In a perfect world, the same Business Key value always means the same real world phenomenon, regardless of the source system where it is encountered (for example, same Person Id always implies the same person, regardless of source system). Also, in a perfect world, business people should see the Business Key in the source system user interface as well as use it naturally for identification purposes in their daily communication.
In a Data Vault solution its technical purpose is to identify data, which is not really the same thing, as the Business Key, as understood by a business person, should sometimes implicitly include a context that is not visible or even identified by the business person using it.
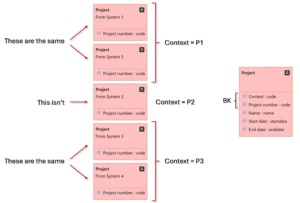
For example, a person may use a Project number as a Business Key to identify a specific project. This Project number identifies the project in the project management system that the person as well as several other persons in the same business area are using. However, in another business area in the same company, there may be another project management system that uses completely different project numbers. The numbers may also be completely or partially overlapping with the first system, meaning that the same project number in this other system does not mean the same project in the first system. In this case, the source system is the context within which the Project id is unique and therefore correctly identifies a specific project. So, when loading project data into the DW, Project number is not sufficient as a Business Key as it needs the context info, the source system code or similar, to be unique when crossing system boundaries.
This also leads to the question: if the proposed Business Key (just Project id) is not the same across different systems, should Project from these different systems be modeled as different classes? This is of course a design choice which affects the point in the process when the different project versions will be merged, if at all. Here adding the context as an explicit attribute can be used to treat what in reality is the same thing, as the same thing, instead of separating things because of a technical detail.
DSharp Studio automates this using Key Groups, without the need to add new attributes.
A Few Words About Key Groups
A Key Group provides the context of the key within which it is guaranteed to be unique and represent the same real world thing, without the need to add an extra and somewhat artificial attribute to the class.
You can use any string as a Key Group. In a real solution, it may not make sense to use a system name as a context, since you might later want to associate another source system’s data to the same Key Group, in which case using the original system name as Key Group name for the new system as well may cause confusion. Instead, use some sort of naming convention, like ProjKG1, ProjKG2 etc. Alternatively, if there is a clear context that you can use instead that is closer to the business case, use that (for example, HR, HealthCare etc). But, as usual, whatever works for your solution.
You can also use the syntax *=!s, which will automatically add the source schema name to every hash calculation. This makes sense when you want to totally separate the data depending on the source. An example of this would be a multitenant solution, where the source corresponds to each tenant name: setting the Key Group to *=!s for any class then guarantees that the same hash is not produced from two different sources. This may or may not be a good idea, as you lose the automatic data integration capability of the Data Vault concept. For example, no longer will the same Person id match on hash level from any two sources. On the other hand, this method might work extremely well for Contracts, where Contract number may be overlapping in the different sources, but representing a different actual contract.