What We Learn
We learn how to fine-tune how individual rows are marked as deleted (D) when state handling is turned on for a class, even for incremental loads.
Scenario
We start loading Project task data from ProjMasterGardening. The data provider will not be able to provide us with material for a full load. We still need to track how rows are deleted in the source system.
We need to be able to correctly decide whether to mark a specific row as deleted or not in the case when the source data is “incomplete”. This decision. can normally be made only when performing full loads, in which case any row missing from the material can be considered to be deleted. In case of an incremental load, we simply cannot just mark any missing row as deleted, as we only expect new and changed rows to be included in the source data anyway. In this case, an earlier loaded row not being present in the current material is assumed to not have changed, as opposed to having been deleted.
Using the D♯ parameter Ignore when setting deleted state we can define a SQL query that returns all the hashes that we shouldn’t mark as deleted after a load. This way we can provide an algorithm that applies the deletion detection mechanism only to the data that could be in the source data, but leaves the missing data unhandled, assuming it still exists in the source.
For this to work, the custom SQL code must tell the truth. To ensure this is the case, the query needs to be compatible with what the source system actually provides on a nightly basis. This will require planning together with the source data provider and agreeing on the content of the data and then making it happen as agreed. The goal of this planning is to define data sets to which some logic can be applied so that the deletion detection can be carried out correctly.
In cases where the SQL code can’t be created to be 100% faultless, a full load should be performed every now and then in suitable intervals in order to reset the correct states.
In our example, we have agreed that the source data contains all the currently existing tasks of those projects for which any task is new, changed or deleted since the last load. You may now start to think about how you would design a query that finds all tasks that we don’t expect to see in the source.
Modeling
Have a look at the data and model accordingly. Modeling this new content is quite straightforward, so you should end up with this model:
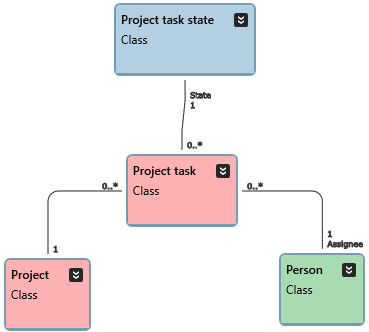
The details are as follows:
| do this… | …and this will happen |
|---|---|
|
For Project task, set the Primary key to be Project, Task number and Assignee. |
Project task is represented by a link table in the Data Vault. NOTE: The logical “source primary key”, in this case is just the combination of Project and Task number. However, as the key type is PK and the class will be represented by a link and not a hub, we also need to include all references that would trigger a change in the corresponding link table’s hash value. Hence we always need to include the references to non-Description classes in our Primary key. If we don’t, in this case, a change of assignee would go unnoticed by the loading mechanism, since it would always produce the same Project/Project task number -based hash, regarding of who the assignee is. |
|
For Project task, set State tracking method to Simple. |
The loading mechanism may try to mark individual rows a deleted if they are not present in the sources. |
Mapping
The mapping is a trivial 1:1 mapping between source and class. Add the mappings to the existing mapping file containing the ProjMaster Gardening mappings.
Refresh and Inspect
Refresh D♯ Engine with the current model export and mappings.
Deploy the Changes And Try It Out
Deploy the new classes Project task, Project task state.
After deploying:
| do this… | …and this will happen |
|---|---|
|
For Project task, activate Soft delete by setting the Soft delete parameter value to true in the D♯ Engine UI. |
The Project task view will hide tasks that appear to be deleted from the source. |
The test script will guide you through the process where you first load the data without correct deletion detection and then with it.
Next, walk through the process described in the script.
| Script | Source data | Main points of interest |
|---|---|---|
| Step 1:
Load data without state handling rule
|
Two separate batches, one full load and one incremental containing tasks from only one project. | All tasks not present in the incremental load will be hidden from the view, which is not what we want. |
| Step 2:
Load data with state handling rule
|
Re-run the same batches but with different settings. | After installing the deletion detection algorithm, only the task that we think should be hidden is actually hidden. Also notice that the assignee for task 2 has changed. |