What We Learn
We learn how to implement a loading mechanism that only loads the latest version of the data from a set containing multiple versions. We also see how we can batch load the older versions in one go.
Scenario
We get a new source for Person data, PersMaster Light, which provides us with basic person data that is compatible with our model, but the data provided is versioned.
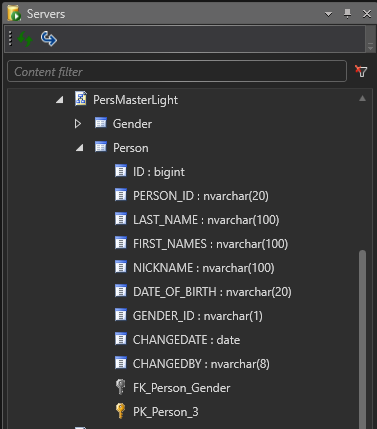
Use D♯ Engine’s Data Grid to verify that the table contains versioned data and that it is compatible with what we already have. Specifically:
- Persons are identified by a compatible set of person ids
- Gender uses the same codes as the original PersMaster, so we don’t need to define any Key Groups
Modeling
After having looked at the data, we see that it is structurally compatible with our current model, except for the CHANGEDATE and CHANGEDBY columns. We feel strongly that these columns are purely technical in nature and they exist for the sole purpose of serving the source system, and as such have no place in our model. Hence our model needs to changes.
However, if we would like to import them to the DW, we would do the following:
- We would add them as attributes to Person, but make the attributes’ visibility private. This way they would not show up in the Person view but still be stored in the raw vault.
- We would set the Group property of these attributes to “Technical”, “Admin” or some other descriptive out-of-the-way kind of name. This way they would end up in their own satellites. As a detail, this satellite would not be joined to in the class view due to the attributes’ visibility setting, so there is no performance penalty doing it this way.
Mapping
We will create a new mapping file for ProjMaster Light. The Gender mapping set is identical to the one in the original PersMaster, and in the Person mapping set there is only one relevant detail that differs from its non-versioned counterpart.
| do this… | …and this will happen |
|---|---|
|
Check (x) the VersionColumnIndex for the CHANGEDATE column |
By this, we indicate the column that we can use for sorting the versioned data from older to newer. The hashing procedure will generate code that groups the same business key rows together and assigns number 1 to the latest row’s LoadOrder column in the work table and number 0 to all others. The load procedures will be generated to only load rows having LoadOrder = 1. |
Then you end up with this:
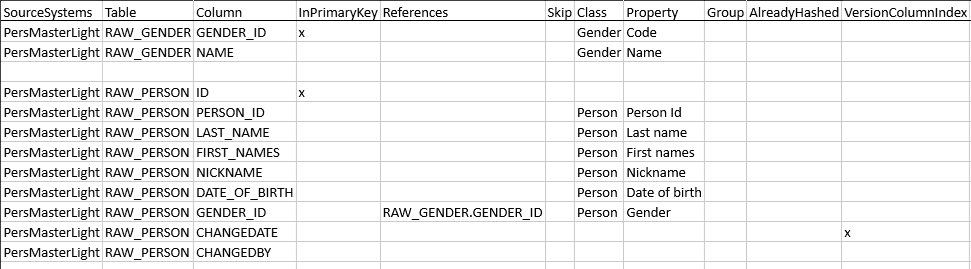
Note that the CHANGEDATE and CHANGEDBY source data columns are declared but not mapped.
Refresh and Inspect
Refresh D♯ Engine with the current model export and mappings.
Using the D♯ Engine UI, check these details:
- view SQL code for the procedure Hash_PersMasterLight_RAW_PERSON to verify the existence and handling of the LoadOrder column
- view SQL code for the procedure Load_hub_Person_from_work_PersMasterLight_RAW_PERSON to verify that the correct row is loaded
Deploy the Changes
We need to deploy Person and Gender, as they are both loaded from a new source. Deploy the classes and run the tutorial command steps.
| Script | Source data | Main points of interest |
|---|---|---|
| Step 1:
Load versioned person data in batches
|
Versioned project data from a new source. | As this is the first time the data is loaded from a new source, we want to load all versions of the data starting from the oldest version up to the latests one. This is done manually using a D♯ UI command. Please refer to the script for details.
Verify that all versions of the data have been loaded. |
| Step 2: Load only latest version | Versioned data is reloaded with new rows present (but also all the older ones) | Older versions should not be reloaded for any person.
The latest version not already in the DW should be loaded. |